Findings Overview
1. Training Set Results
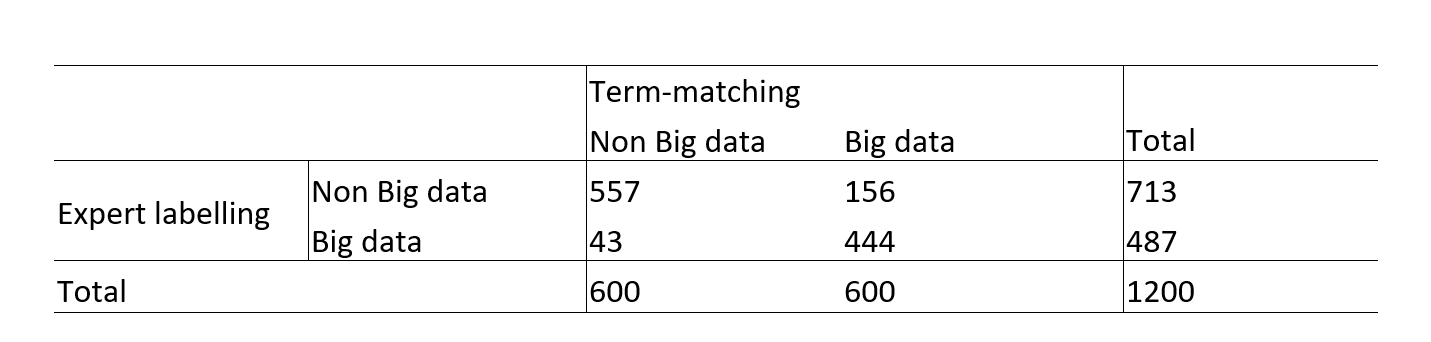
Among 1200 abstracts, 40% (487/1200) were big data related. Most of the error from the term-matching in labeling is to classify an abstract that is non big data related as big data based on the name (156/713) 21.8%.
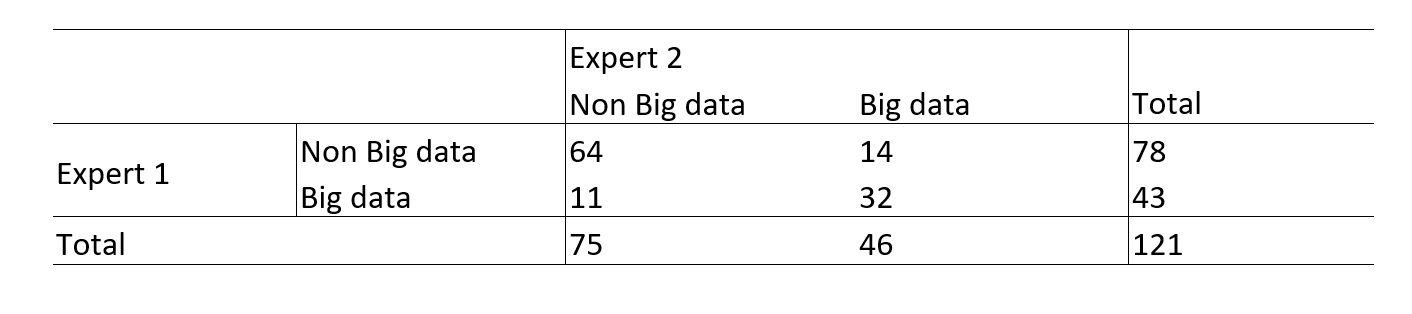
There was no high difference in labeling between experts. Overall, 79.3% ((64+32)/121) of abstracts have been identically labeled by the 02 experts. Most of the assigning difference is from assigning a non big-data abstracts as big-data.
2. KNN Performance on Test Set
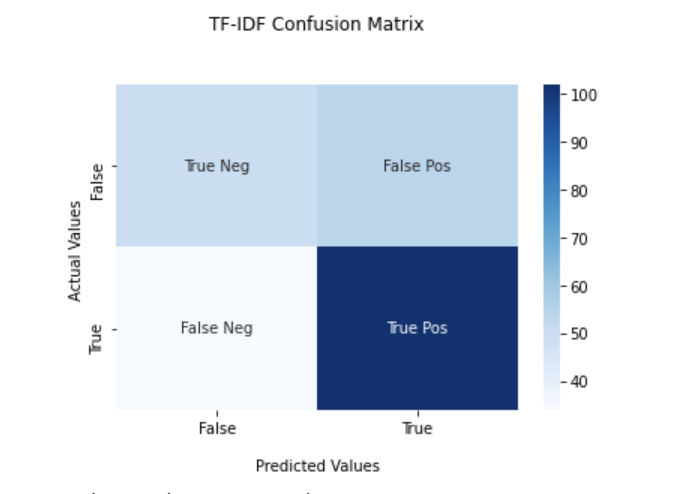
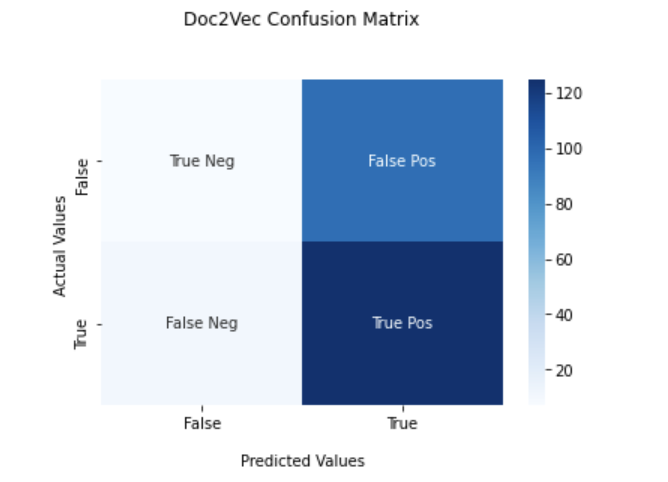
Above are confusion matrices that were created from testing the labeled data on a trained KNN classifier. As can be seen by the matrices above (in section 1), both vectorization methods had a fairly large amount of false positives. This could be one explanation for the large number of abstracts that were identified as big data.
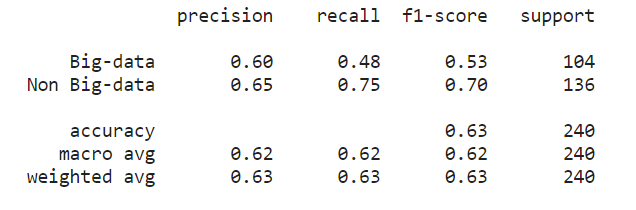
The weighted average precision for TF-IDF was 0.63, as was the weighted average recall. These metrics were calculated based on the manually labeled training set. The precision means that 63% of the abstracts were identified as big data were in fact relevant to big data. The recall means that 63% of the abstracts relating to big data were selected as big data by the classifier. Further refinements on the model such as changing the number of nearest neighbors could increase the precision and accuracy.
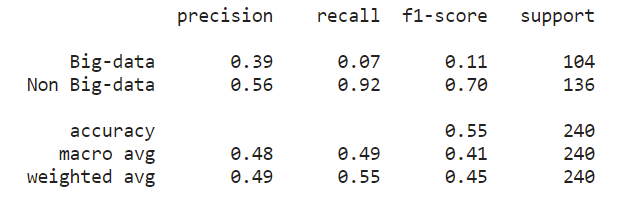
The weighted average precision for Doc2vec was 0.49, a the weighted average recall w as 0.55. These metrics were calculated based on the manually labeled training set. The precision means that 49% of the abstracts were identified as big data were in fact relevant to big data. The recall means that 55% of the abstracts relating to big data were selected as big data by the classifier. Further refinements on the model such as changing the number of nearest neighbors could increase the precision and accuracy.
3. KNN on Full Corpus : Big Data Corpus
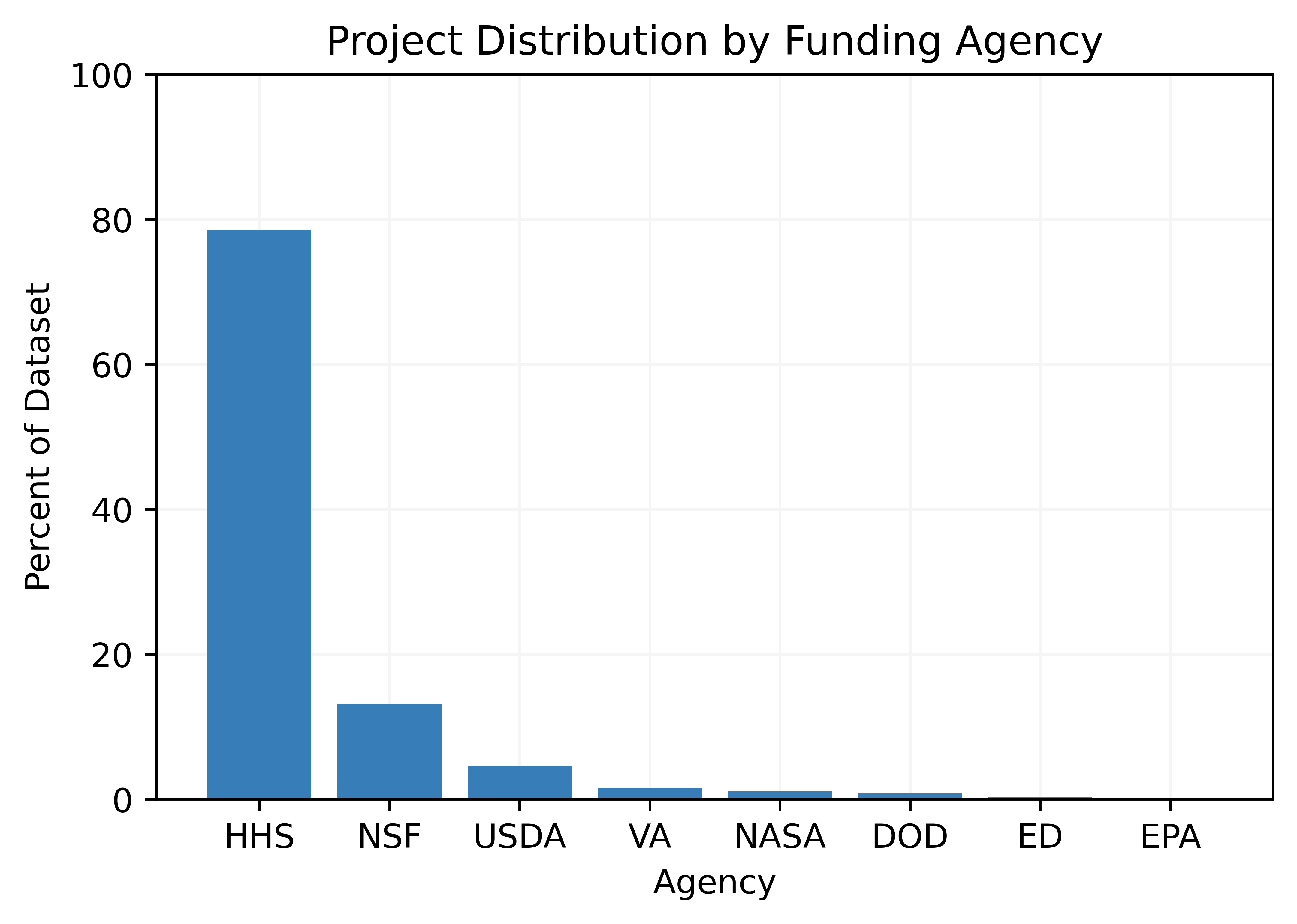
257,123 abstracts were identified using TF-IDF to vectorize the text and KNN to classify it. 484,362 abstracts were identified using Doc2Vec to vectorize the text with the KNN classifier The chart on the left shows the number of projects mentioning Big Data over time. The numbers are fairly stable. The chart on the right shows the number of projects that mention Big data by agency over the time period 2008-2020. 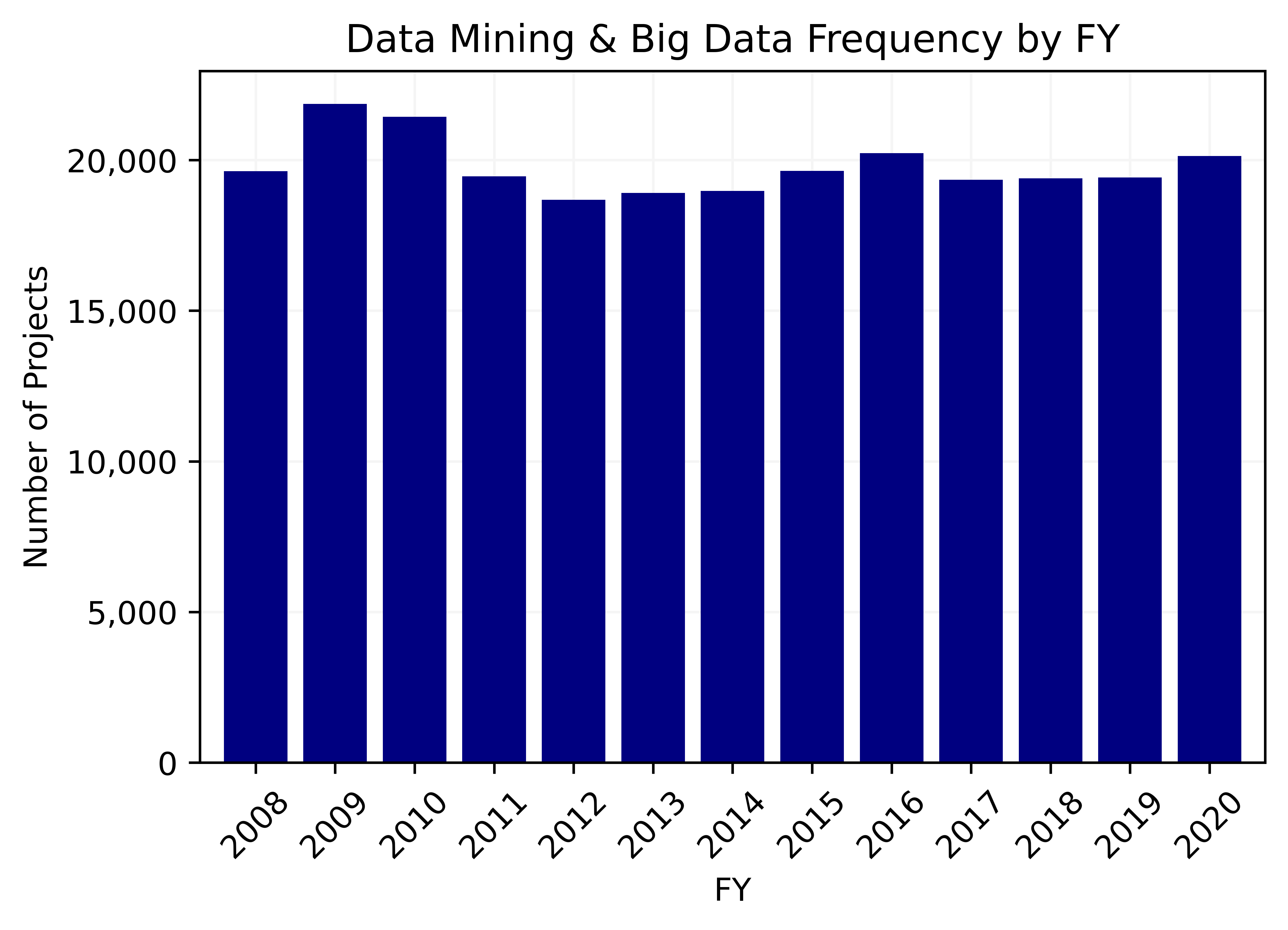
Through vectorizing the abstracts in our corpus and using a classification method, it was possible to identify whether abstracts were related to big data. Once these abstracts were identified, topic models were run on them to further identify sub-theme trends.