Methods
1. Definition of Digitalization
1.1 Initial Definition
Initially, Organisation for Economic Co-operation and Development (OECD) literature was reviewed to define digitalizaiton. The initial definition was “Digitalization is the innovative application and adoption of emerging technologies and data that promote social, economic, and cultural progress.” A list of key technologies consistently mentioned as key to digitalization was also created. These included: internet of things, artificial intelligence, 5G, distributive ledger technology, cloud computing, robotization, autonomous machines, big data, and cloud computing among many others.
1.2 Finalized Definition
All of the literature sources were from the OECD and most from the G20 summit so the definitions were very similar. Because of this, a broader range of sources (National Academy of Science, Engineering, and Medicine, Google Scholar, UVA Virgo, Urban Institute, Brookings, etc.) was explored to create a more precise definition:
“Digitalization is the innovative adoption of emerging technologies to transform analog data into digital language, which, in turn promotes social, economic, and cultural progress.”
The key difference in this definition is that digitalization is focused on the adoption of these technologies rather than the conversion of analogue data to digital data (digitalization) and applying it to the world/businesses (digital transformation).
1.3 Narrowed Definition
The definition of digitalization was still incredibly broad and could encapsulate most of the technological change in the past couple of centuries, so after speaking with the project’s stakeholders, it was decided to focus more closely on the theme of Big Data. A definition for this sub-theme was developed by looking at dictionaries and academic sources such as the OECD. Three different definitions were used:
Oxford Languages (Google) Definition:
“extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions.”
Gartner Definition:
“‘Big data’ is high-volume, -velocity and -variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.”
UNCTAD 2019 Digital Economy Report Definition:
“The term ‘big data’ has been popularized to denote the broader range of data that are increasingly available to individuals, firms and societies. The ‘big’ in big data can be defined along a number of axes: in terms of the growing volume of data available (e.g. from online transactions, sensors, devices); the wider variety of data that might be interpreted and combined with other data (e.g. unstructured data such as video and internet logs); and velocity, where data is generated very rapidly, and sometimes requires real-time interpretation (Laney, 2001).”
2. Literature Review of Methods
A literature review was conducted to explore possible vectorization and classification methods to use. We looked at Doc2Vec, Word2Vec, and TF-IDF as ways to vectorize the text corpus. It was decided to use Doc2Vec and TF-IDF initially. Doc2Vec works best to capture the meaning of words in context and TF-IDF works to capture the meaning of each individual word. KNN and SVM were explored as text classification methods. KNN is the most widely used method so it was selected to be used initially. In future steps, SVM will be explored.
3. Learning Sample
The goal of the learning sample was to create a training set where half of the documents related to Big Data and half did not. Term-matching was used to find the subset of abstracts which contains the words big data/ big_data/big datum. 4,684 abstracts were found (from the 1,143,869 abstracts) containing the word big data. From both the set of abstracts containing the words big-data and those without the word big-data, the same number of abstracts were sampled to balance the learning sample. 600 abstracts were drawn from each set and to obtain a learning sample of 1,200 abstracts. Based on the definition of big data, 12 experts were trained to manually label abstracts on whether a given abstract is big data related or not. Then, 100 distinct abstracts were randomly assigned to each expert to match to the 1,200 abstracts from our learning sample. To track any difference in understanding the definition of big data between experts, 10 abstracts were randomly selected from each expert and assigned to a different expert for labeling. The difference in labeling the same abstract from 2 experts allowed the difference in understanding the definition of big data to be captured.
4. Text Vectorization
4.1 TF-IDF
Term Frequency-Inverse Document Frequency is a vectorization method that represents a document as a set of vectorized words.
4.2 Doc2Vec
Doc2Vec is another method to vectorize a document, which takes into account the semantics of the words as they appear in the abstracts. For each document/abstract, Doc2Vec creates a matrix of the words in the document as well as a paragraph ID allowing for the document to be processed as a whole as opposed to the individual words, which Word2Vec does,
5. Supervised Learning: KNN
5.1 Method
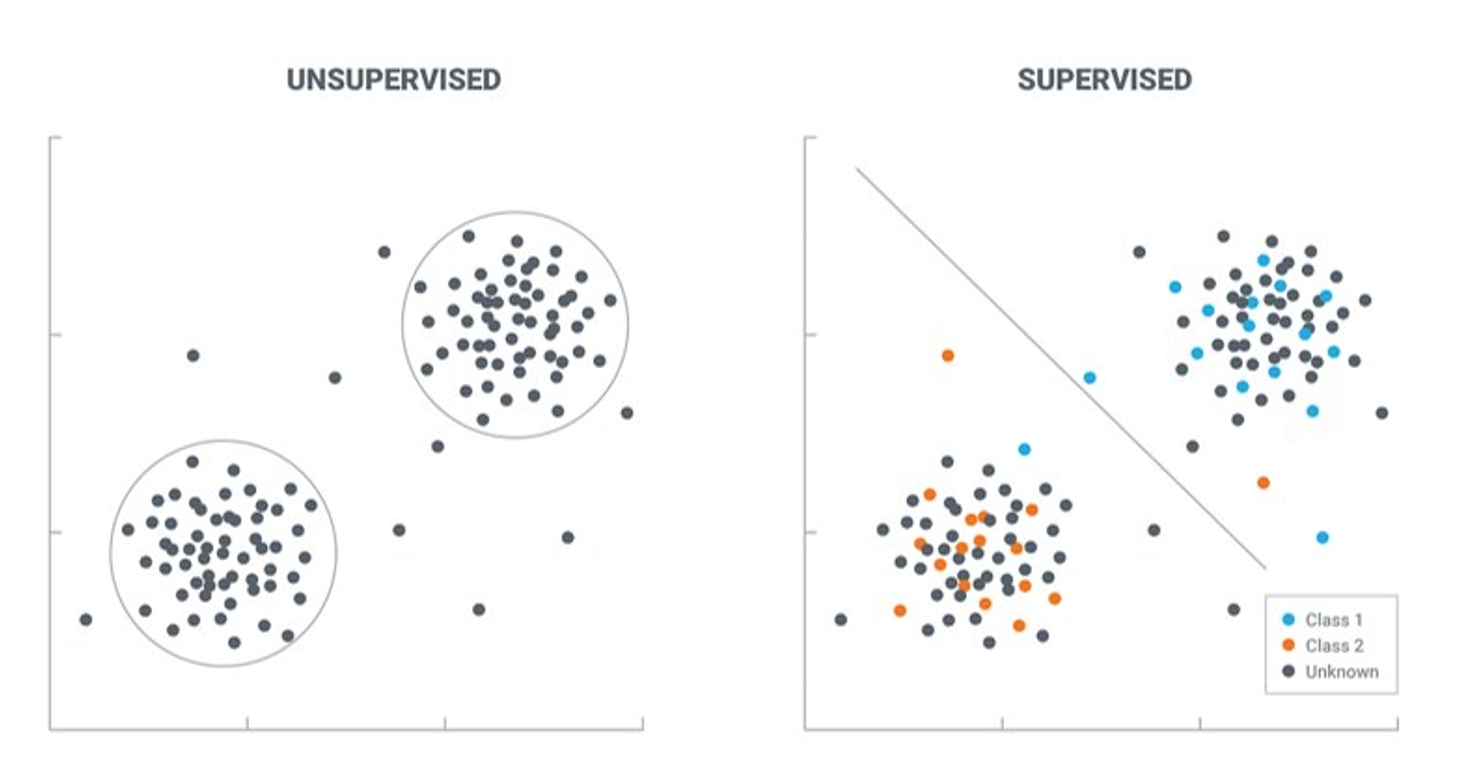
Graphic Source: https://lawtomated.com/supervised-vs-unsupervised-learning-which-is-better/
A supervised learning approach was used to label abstracts as big data related or not. Compared to an unsupervised method, this approach identifies abstracts that are theme relevant while also measuring the performance of the classifier algorithm. This approach requires a set of labeled data where the labels are binary: big data or not.
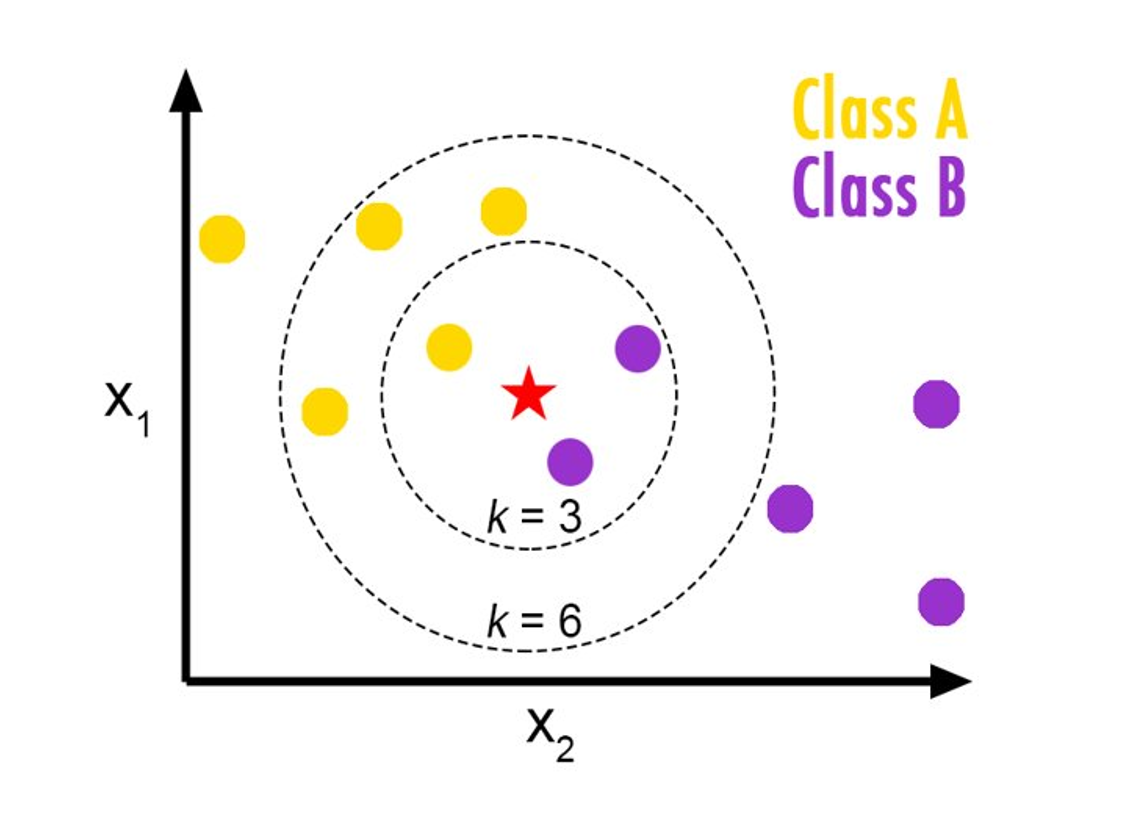
Graphic Source: T. T. Dien, B. H. Loc and N. Thai-Nghe, “Article Classification using Natural Language Processing and Machine Learning”; https://medium.com/@srishtisawla/k-nearest-neighbors-f77f6ee6b7f5
The method works by looking at the vectorization of each abstract and classifying it into a class based on its nearest neighbors. For the purposes of this project, we used 10 nearest neighbors.
The learning sample was randomly split into a training sample (80%) and a test sample (20%). The training is used to feed the KNN classifier and extract the key features from the prediction. The test sample is used to evaluate the model performance. The trained model was then applied to the abstracts throughout the entire corpus.
5.2 Evaluation
A confusion matrix can evaluate the performance of classification arguments. A true positive (TP) represents the number of properly classified abstracts as big data. A true negative (TN) represents the number of correctly classified abstracts that are not related to big data. A false positive (FP) represents the number of misclassified documents as being big data that are actually not related to big data. Finally, a false negative (FN) represents the number of abstracts misclassified as not being related to big data when it is about big data.
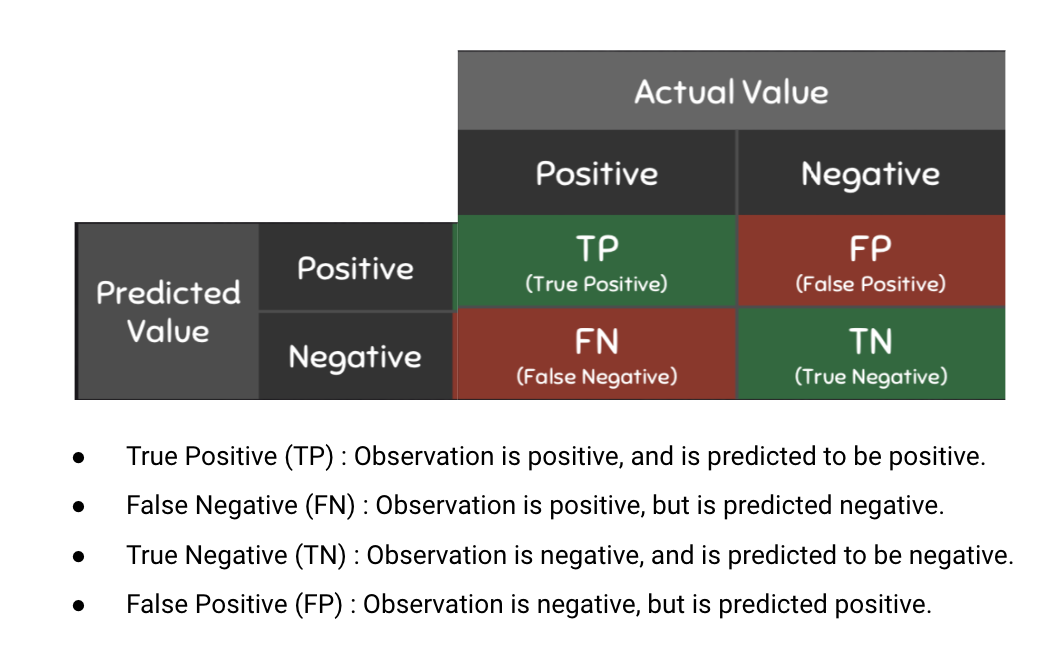
Graphic Source: https://www.kdnuggets.com/2020/04/performance-evaluation-metrics-classification.html
We can use these metrics to calculate the accuracy, precision, recall, and F1 score, whose calculations are shown in the graphic below.

Graphic Source: https://www.tutorialexample.com/an-introduction-to-accuracy-precision-recall-f1-score-in-machine-learning-machine-learning-tutorial/
6. Topic Modeling of Trends in R&D
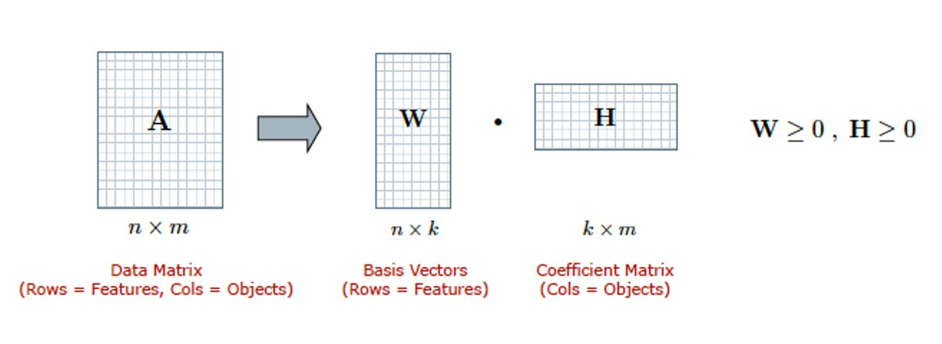
For topic modeling, Non-Negative Matrix Factorization (NMF) was used. NMF is an approximate matrix decomposition that in the context of topic modeling,finds the document-topic and topic-term weights through iterative optimization (D. D. Lee & Seung, 1999). The input to NMF includes term frequency-inverse document frequency (TFIDF) weights by document.
NMF was run both sets of abstracts identified as big data. From this, 10,20, and 30 topics that commonly occurred in the sets were identified. The topics were composed of words that defined them to be unique and also appeared often. The resultant topics from the topic models were analyzed by examining their weights over time. This allowed the relative prevalence of each topic in the corpus of big data related abstracts over time to be roughly characterized.
The document-topic distribution was used to obtain the topic weights for each abstract. Then, for each year the means of the weights of the topics are calculated for the project abstracts that have the given start year. The relationship between mean weight and year for each topic was modeled using linear regression, thus capturing the trend of the topic weights over time.
Simple Exploratory Data Analysis (EDA) was also run on the abstracts identified as big data. Through this, the departments with the most abstracts relating to big data were identified. It could also be explored which agencies contributed the most, but as expected most of them were from HSS.
7. Future Work
In the future, an initial priority would be to run the Doc2Vec model with an increased vector and epoch(number of times the model is run) size. It would also be useful to continue to optimize the classification method and explore other methods such as SVM. It would also be useful to increase the number of training documents so that the methods can be more thoroughly trained.
Sources
G20 Research Group. (2018). G20 Digital Economy Ministerial Declaration. http://www.g20.utoronto.ca/2021/210805-digital.html
International Telecommunication Union. (2018). G20 Digital Economy Task Force: Toolkit for Measuring the Digital Economy. https://www.itu.int/en/ITU-D/Statistics/Documents/g20-detf-toolkit_FINAL.pdf
Ministry of Foreign Affairs of Japan. (2018). G20 Ministerial Statement on Trade and Digital Economy. https://www.mofa.go.jp/files/000486596.pdf
Organisation for Economic Co-operation and Development. Digitalisation and Innovation. https://www.oecd.org/g20/topics/digitalisation-and-innovation/
Organisation for Economic Co‐operation and Development. (2016). G20 Innovation Report 2016. https://www.oecd.org/china/G20-innovation-report-2016.pdf
Organisation for Economic Co‐operation and Development. (2017). Key Issues for Digital Transformation in the G20. https://www.oecd.org/g20/key-issues-for-digital-transformation-in-the-g20.pdf (accessed on 16 July 2018).
Organisation for Economic Co‐operation and Development. (2017). The Next Production Revolution: A report for the G20. https://www.oecd.org/g20/key-issues-for-digital-transformation-in-the-g20.pdf.
Organisation for Economic Co-operation and Development. (2018). Bridging the Digital Gender Divide: Include, Upskill, Innovate. https://www.oecd.org/digital/bridging-the-digital-gender-divide.pdf
Organisation for Economic Co-operation and Development. (2019). Challenges to Consumer Policy in the Digital Age. https://www.oecd.org/sti/consumer/challenges-to-consumer-policy-in-the-digital-age.pdf
Organisation for Economic Co‐operation and Development. (2022). Recommendation of the Council on Artificial Intelligence. OECD/LEGAL/0449